RTO With Cohesity @ vRetreat
How Cohesity’s Approach to VM Backup Affects the Recovery Time Objective
This week I attended another vRetreat online, this time featuring data vendor Cohesity who I saw presenting at the (in-person) event last year. These are great events, and the small panel of delegates works well in the virtual format.
One thing that stood out to me in their presentation was the focus on the Recovery Time Objective (RTO)- in essence how long it takes to recover from an incident. In this post I will briefly discuss how I understand the definition of RTO before looking at how the Cohesity products work to keep this time down when working with Virtual Machines.
Recovery Time Objective
There’s plenty of material out on the interwebs which will explain RTO in great detail, but I’m taking the definition to be:
“the expected length of time between an incident occurring and users being able to work normally again”
As this diagram shows, the Time can be split into a number of notable sections, I’ve chosen the following three:
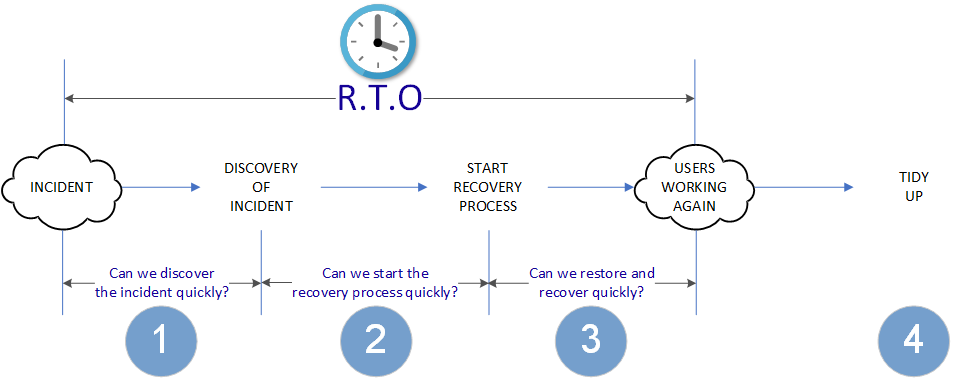
- Discovering the Incident. How long is it before we notice something is broken? Do we have to wait for a user to contact the service desk, or do we have responsive monitoring and alerting in place?
- Starting the Restore. How long does it take to actually start the restore operation? Is there a clear process to be followed? There might be internal decisions to be made as to whether to kick off a backup restore or attempt an in-place repair. Does somebody need to physically power on some equipment or find and load some tapes before a backup restore can commence?
- The Restore Operation. How long does it take between “Go” being pushed on the restore console and the service being usable again?
You’ll notice there’s also a fourth section on the diagram- the “Tidy Up”. This is all those processes that need to happen after the user is working again to get the system back into a normal state. This might include things like tidying up the original (broken) copies of the VM, returning a backup tape to the library, or investigation of the root cause. In any of these cases, I’ve put this step outside of the RTO as by the definition above, the Users are working normally again.
Ransomware Detection
Tied with an alerting mechanism, this helps address our question in point 1 above- “Can we discover the incident quickly?”. The sooner someone in IT is aware that a ransomware infection has happened, the quicker a response can be started.
Additionally, Regular point-in-time snapshot backups make it easier to spot the time the infection started (or if not the point of infection, at least when the malware started acting) and the more granular the timestamps the less data is potentially lost between a backup and the incident. But we’re straying into RPO, not RTO, there.
Starting Restore
Most of the time when responding to a major incident and orchestrating a restore operation the user interface will be key to assessing the situation and bringing services back online. Cohesity offers a clean and tidy web-based UI, complete with the now-obligatory Dark Mode.
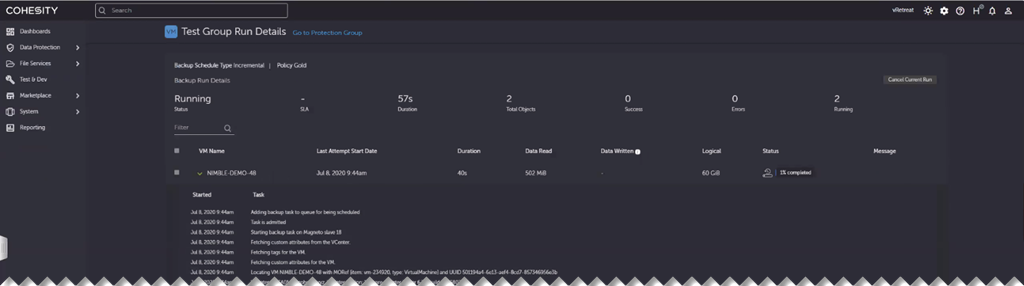
Whilst the platform isn’t going to make those go/no-go decisions on kicking off a restore- it can influence that decision. Because the restores are so quick (as we’ll see shortly) the discussion on whether to repair or restore might favour the latter. It’s also possible to bring up the VMs in a network-disconnected state without touching the production systems so that once any discussions are complete the restore is even quicker (or if the repair option is chosen then that restore can just be cancelled)
Restoring User Service
Once recovery is started in Cohesity Data Protect an NFS datastore is created on the Data Platform- the VMDK is already here so there is no need to spend time at this point moving blocks across the network. The NFS datastore is mounted within vCenter and the VM registered and at this point the VM can be powered on and the users can get working again.
Once service has been restored, the longer process of putting the VM files back where they belong is achieved with the hypervisors own Storage vMotion technology (the fourth step above). Applications are available throughout this, and once the Cohesity datastore has been cleared, it is unmounted from vCenter.
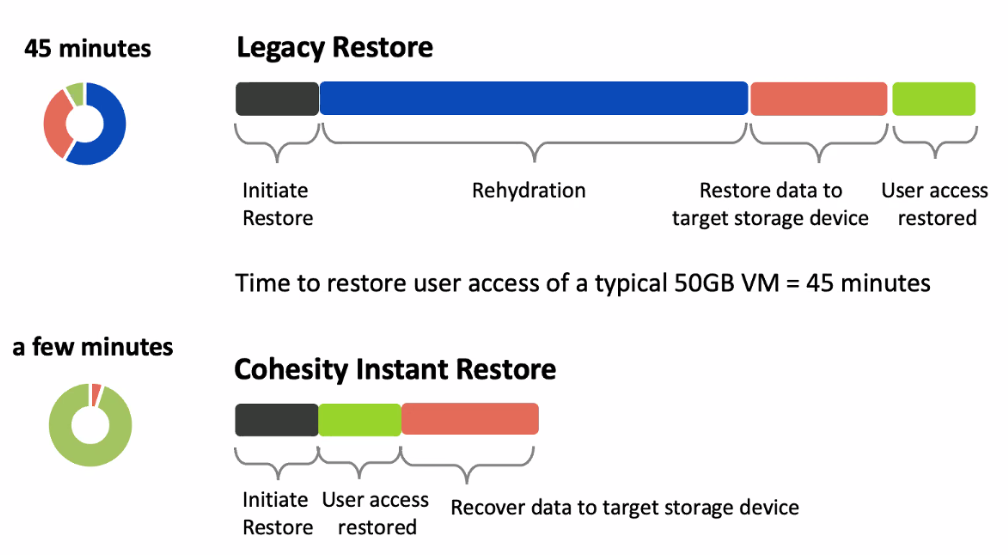
As this slide extract from the Cohesity presentation shows, one of their big selling points is this quick recovery process. Notice how the “Recover data to target storage device” is positioned after the User access is restored.
Thanks to Patrick Redknap and the Cohesity team for hosting this informative event, and I look forward to the next one. For more information about Cohesity, check out their website: www.cohesity.com
Please read my standard Declaration/Disclaimer and before rushing out to buy anything bear in mind that this article is based on a sales discussion at a discussion at a analyst session rather than a POC or production installation. I wasn’t paid to write this article or offered any payment, although Cohesity did sponsor a prize draw for delegates at the event.