The Alerting Cycle
Ever had an incident where you think “we could have resolved this quicker if we’d have spotted that X was happening”? Automated alerts can help.
When you have an incident, when something goes wrong, obviously you need to fix the service and get it running again. It’s also important to try and establish the root cause to prevent the fault occuring again. There’s a third workstream however, alerting:
Were there any symptoms that we could have detected which could have either enabled us to address the fault before it impacted users, or otherwise helped us to a speedy resolution?
Most IT organisations will have something in place to spot a failure in service -“The website is down” - but there’s also an important place for spotting the symptoms that either led up to or caused the failure. If IT can pick these up in advance the failure may never happen.
Whilst the root cause of this particular incident may have been addressed, similar incidents with similar symptoms could occur in the future, or the root cause fix may be undone or broken unwittingly by a future change. This is where automated alerts come in. The alert could be an email, Instant Message, a log entry in a feed, or even an old-school Pager alert but the right message at the right time can help speed along the incident resolution process.
I see alerting as a cycle of improvement, all tied in with the parent service:
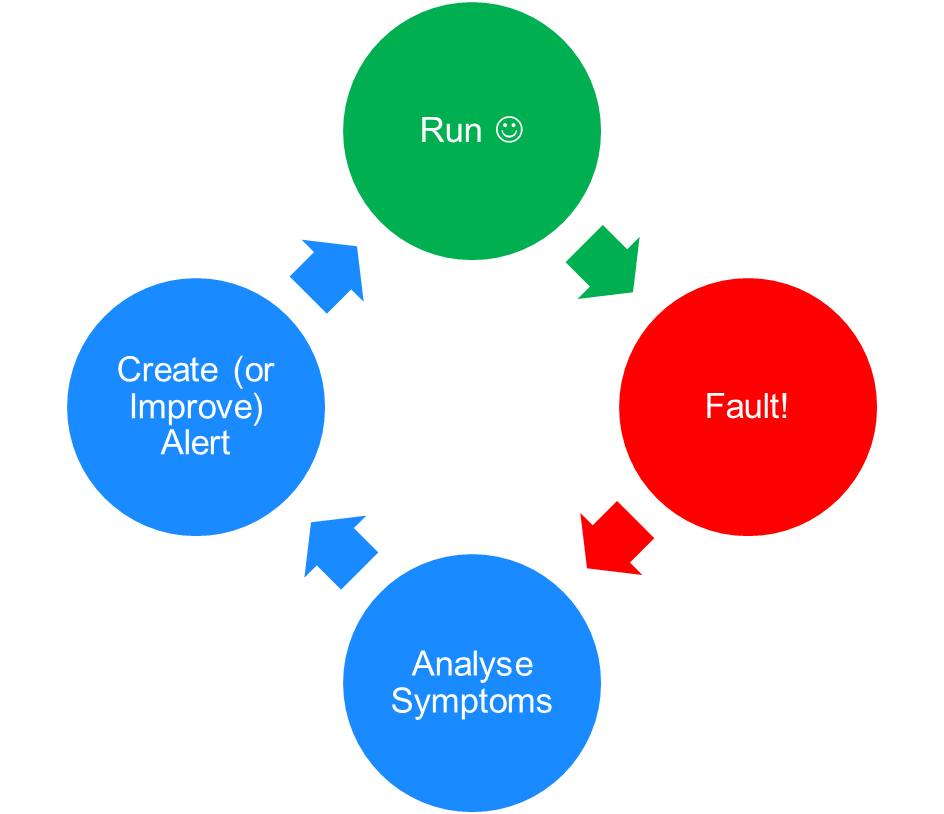
The application or service is happily running until it encounters a fault. At this point usual incident management processes kick in, but alongside (or as part of) those the IT operations team are looking for clues or symptoms which align with the fault. These symptoms can be many things. For example it could be a particular log entry in a syslog feed, it could be a drop in traffic to a web server, an increase in http redirect responses sent to a load balancer, an account expiring, or a vMotion event on the database server….. If the team can spot what is related to the incident but isn’t normal and in someway quantify it, you have a suitable trigger for your alert.
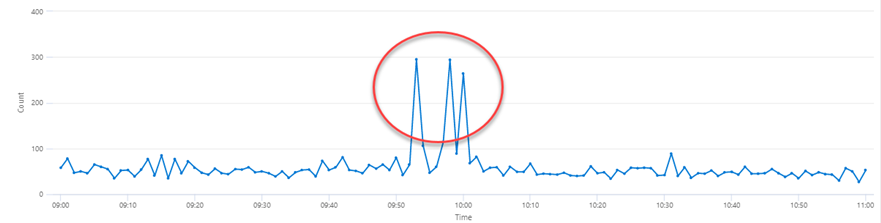
In the following graph (real data gathered from Azure Log Analytics following a real incident) we can see that the background level of this particular metric was around 50-100, and interrogating historic data established that this is the case beyond the timeline of this graph. When the incident occurred we had peaks stretching up to 300. As the symptoms that caused this spike were likely to be tied to the incident under investigation we could use a “Count > 200” as a trigger for a future alert.
Discovering this trigger answers the first of three important questions:
- What am I looking for?
- Who do I need to tell about it?
- Is there any automation I can trigger?
The second question “Who do I need to tell about it?” is also important. With any monitoring and alerting solution it’s easy to overwhelm a feed, team, or individual with alerts and if someone is receiving too much noise they won’t spot the messages they need to act upon. Equally, sending alerts to an individual or group who won’t be able to act on them is pointless. The recipient is important and so is the message- if the SysAdmin team get an alert saying “HTTP 300 errors are above threshold” that might not produce the preferred result, whereas a message saying “HTTP 300 errors are above threshold on the ServiceDesk application, this has previously indicated an underlying connectivity issue -knowledgebase article #12345” is more likely to lead to a speedy resolution.
With an alert created and going to the correct team, it’s important to make sure that it isn’t forgotten -especially if it doesn’t trigger regularly. One solution here is to use tagging or naming to tie the alert in with the parent service/application. When that service has it’s regular review (you do do those, don’t you ;) ) or is even decommissioned, the connected alert isn’t forgotten about. To put it another way, don’t let the alerts become detatched from the Application lifecyle.
The final question was “Is there any automation I can trigger?”. Getting this bit right is the gold-level achievement for any IT service, if you can spot an incident as it occurs and trigger an automated action that resolves it with no human interaction then you have not only minimised the impact on the users but also potentially freed up your IT team to be able to fix another issue, or improve another service.
So now the alert is created, the service is back in it’s “Run” state at the top of the cycle, and everything is good. But the next week another fault occurs. This is where the cycle continues- in analysing the symptoms again is another alert required, or do we need to modify the current alert? Modification is tied to those three questions above. It might involve changing the criteria (did the alert not trigger because the threshold was too high or the scope was too narrow?) or the recipients (if team X had recieved this alert instead of team Y would this have been resolved quicker or prevented?), or the automation (the automation ran but didn’t fix it in this scenario).
As with all components of an IT system it’s all about continuous improvement. How can we make this “better” in the future?